


Simple Storage Service (S3):
→ Amazon S3 is an object storage platform that allows you to store and retrieve any amount of data, at any time, from anywhere on the web.
-> Let's understand the different storage types in detail and see where S3 fits in.
Block storage
A block is a range of bytes or bits on a storage device. Block storage files are divided into blocks and written directly to empty blocks on a physical drive.
Each block is assigned a unique identifier and then written to the disk in the most efficient manner possible. Since blocks are assigned identifiers, they do not need to be stored in adjacent sections of the disk. Indeed they can be spread across multiple disks or environments.
With relational databases, you might only need to retrieve a single piece of a file, such as an inventory tracking number, or one specific employee ID, rather than retrieving the entire inventory listing or whole employee repository.
File Storage
Historically, operating systems save data in hierarchical file systems organized in the form of directories, sub-directories and files, or folders, sub-folders, and files depending on the operating system.
For example, if you are troubleshooting an issue on a Linux distribution, you may need to look in /var/log or /etc/config. Once inside these directories, you need to identify which file to explore and open. When using a file-based system, you must know the exact path and location of the files you need to work with or have a way to search the entire structure to find the file you need.
Object Storage
Object storage is a flat structure where the data, called an object, is located in a single repository known as a bucket.
Objects can be organized to imitate a hierarchy by attaching key name prefixes and delimiters. Prefixes and delimiters allow you to group similar items to help visually organize and easily retrieve your data.
In the user interface, these prefixes give the appearance of a folder and subfolder structure but in reality, the storage is still a flat structure.
→ Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. You have access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of websites.
→ In Amazon S3 object storage, you can organize objects to imitate a hierarchy by using key name prefixes and delimiters. Prefixes and delimiters allow you to group similar items to help visually organize and easily retrieve your data. In the user interface, these prefixes give the appearance of a folder/ subfolder structure but in reality, the storage is still a flat structure.

Organizing objects using prefixes:
You can use prefixes to organize the data that you store in Amazon S3 buckets.
A prefix is a string of characters at the beginning of the object key name. A prefix can be any length, subject to the maximum length of the object key name (1,024 bytes).
You can think of prefixes as a way to organize your data in a similar way to directories. However, prefixes are not directories.
Bucket overview:
Buckets are permanent containers that hold objects.
You can create between 1 and 100 buckets in each AWS account. You can increase the bucket limit to a maximum of 1,000 buckets by submitting a service limit increase.
Bucket sizes are virtually unlimited so you don't have to allocate a predetermined bucket size the way you would when creating a storage volume or partition.
An Amazon S3 bucket is a versatile storage option with the ability to: host a static website, retain version information on objects, and employ life-cycle management policies to balance version retention with bucket size and cost.
Bucket names must:
This identifies the bucket URL in the format of the bucket name/ region endpoint.
Be unique across all of Amazon S3
Be between 3-63 characters long
Consist only of lowercase letters, numbers, dots (.), and hyphens (-)
Start with a lowercase letter or number
Not begin with xn-- (beginning February 2020)
Not be formatted as an IP address. (i.e. 198.68.10.2)
Use a dot (.) in the name only if the bucket's intended purpose is to host an Amazon S3 static website; otherwise do not use a dot (.) in the bucket name.
Bucket limitations:
- Amazon S3 buckets are owned by the account that creates them and cannot be transferred to other accounts.
Bucket names are globally unique. There can be no duplicate names within the entire S3 infrastructure. Once created, you cannot change a bucket name.
Buckets are permanent storage entities and are only removable when they are empty. After deleting a bucket, the name becomes available for reuse by any account after 24 hours if not taken by another account.
There’s no limit to the number of objects you can store in a bucket. You can store all of your objects in a single bucket, or organize them across several buckets. However, you can't create a bucket from within another bucket, also known as a nesting bucket.
By default, you can create up to 100 buckets in each of your AWS accounts. If you need additional buckets, you can increase your account bucket limit to a maximum of 1,000 buckets by submitting a service limit increase.
S3 Object Brief:
Amazon S3 is an object store that uses unique key values to store as many objects as you want. You store these objects in one or more buckets, and each object can be up to 5 TB in size.
An object consists of the following: Key, version ID, value, metadata, and access control information. The object key (or key name) uniquely identifies the object in a bucket.
What is a Key?
- When you create an object, you specify the key name. The key name uniquely identifies the object in the bucket. It is the full path to the object in the bucket.
Version ID
- Versioning is a means of keeping multiple variants of an object in the same bucket. You can use versioning to preserve, retrieve, and restore every version of every object stored in your Amazon S3 bucket. You can easily recover from both unintended user actions and application failures. If Amazon S3 receives multiple write requests for the same object simultaneously; it stores all of the objects.
Value
- Value (or size) is the actual content that you are storing. An object value can be any sequence of bytes, meaning it can be the whole object or a range of bytes within an object that an application needs to retrieve. Objects can range in size from zero to 5 TB.
Metadata
Amazon S3 maintains a set of system metadata. Amazon S3 processes this system metadata as needed. For example, Amazon S3 maintains object creation date and size metadata and uses this information as part of object management.
There are two categories of system metadata:
Metadata such as object creation date is system controlled, where only Amazon S3 can modify the value.
Other system metadata, such as the storage class configured for the object and whether the object has server-side encryption enabled, are examples of system metadata whose values you control
Access control information
- You can control access to the objects you store in Amazon S3. S3 supports both resource-based and user-based access controls. Access control lists (ACLs) and bucket policies are both examples of resource-based access control.
Organizing data using tags:
A tag is a label that you assign to an AWS resource. Each tag consists of a key and an optional value, both of which you define to suit your company's requirements. Tags enable you to categorize your AWS resources or data in different ways.
Using tags for your objects allows you to effectively manage your storage and provide valuable insight into how your data is used. Newly created tags assigned to a bucket, are not retroactively applied to its existing child objects.
You can use two types of tags: Bucket tags and Object tags.
Region location:
Amazon S3 is a globally viewable service. This means that in the AWS Management Console, you do not have to specify a region to view the buckets.
When you initially create the bucket, you must choose a region to indicate where you want the bucket data to reside. The region you choose should be local to your users or consumers to optimize latency, minimize costs, or address regulatory requirements.
Cross-Region Replication (CRR):
If you need data stored in multiple regions, you can replicate your bucket to other regions using cross-region replication. This enables you to automatically copy objects from a bucket in one region to a different bucket in another, separate region. You can replicate the entire bucket or you can use tags to replicate only the objects with the tags you choose.
Same-Region Replication (SRR):
Amazon S3 supports automatic and asynchronous replication of newly uploaded S3 objects to a destination bucket in the same AWS Region.
SRR makes another copy of S3 objects within the same AWS Region, with the same redundancy as the destination storage class. This allows you to automatically aggregate logs from different S3 buckets for in-region processing, or configure live replication between test and development environments. SRR helps you address data sovereignty and compliance requirements by keeping a copy of your objects in the same AWS Region as the original.
S3 Consistency Model:
Amazon S3 now delivers strong read-after-write consistency for any storage request, without changes to performance or availability, without sacrificing regional isolation for applications, and at no additional cost. Any request for S3 storage is now strongly consistent.
After a successful write of a new object or overwrite of an existing object, any subsequent read request immediately receives the latest version of the object. Amazon S3 also provides strong consistency for list operations, so after a write, you can immediately perform a listing of the objects in a bucket with any changes reflected.
There is no charge for this feature and it is available for all GET, PUT, LIST, and HEAD requests, as well as Access Control Lists, object tags, and other metadata. For bucket operations such as reading a bucket policy or metadata, the consistency model remains eventually consistent.
Securing Data Access:
Principle of least privilege:
Least privilege is a security design strategy where granted permissions allow only the minimum necessary rights required to accomplish the task.
When working with Amazon S3, identify what each user, role, and application needs to accomplish within your buckets and then create policies that allow them to perform only those specific tasks.
Security mechanisms:
IAM is used to create users and manage their respective access to resources, including buckets and objects.
Bucket policies are used to configure permissions for all or a subset of objects using tags and prefixes.
Pre-Signed URLs are used to grant time-limited access to others with temporary URLs.
Access Control List (ACLs) to make individual objects accessible to authorized users.
Note: Amazon S3 ACLs are a legacy access control mechanism that predates IAM. AWS recommends using Amazon S3 bucket policies or IAM policies for access control.
Access policies:
Access policy describes who has access to what resources. They attach to your resources, such as buckets and objects, and are also called resource policies. For example, bucket policies and access control lists are resource-based policies because you attach them directly to buckets and objects.
User policies or IAM policies are access policies attached to users in your account. You may choose to use one type of policy or a combination of both, to manage permissions with your Amazon S3 resources.
Bucket policies
To grant other AWS accounts or IAM users access to the bucket and the objects in it, you need to attach a bucket policy. Because you are granting access to a user or account, a bucket policy must define a PRINCIPAL (which is an account, user, role, or service) entity within the policy.
Use a bucket policy if:
You need to grant cross-account permissions to other AWS accounts or users in another account, without using IAM roles.
Your IAM policies reach the size limits for users, groups, roles.
You prefer to keep access control policies in the Amazon S3 environment.
Although both bucket and user policies support granting permission for all Amazon S3 operations, the user policies are for managing permissions for users in your account.
Encrypting Data:
Encryption methods on S3: SSE-S3 uses keys managed by AWS, SSE-KMS uses AWS KMS service to manage keys, and SSE-C provide your keys for encrypting, Client-side encryption you manage.
SSE-S3:
Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3)
When you use Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3), each object encrypts with a unique key. As an additional safeguard, it encrypts the key itself with a master key that it regularly rotates. Amazon S3 server-side encryption uses one of the strongest block ciphers available, 256-bit Advanced Encryption Standard (AES-256), to encrypt your data.
SSE-KMS:
Server-Side Encryption with Customer Master Keys (CMKs) Stored in AWS Key Management Service (SSE-KMS)
Server-Side Encryption with Customer Master Keys (CMKs) Stored in AWS Key Management Service (SSE-KMS) is similar to SSE-S3 but with some additional benefits and charges for using this service. There are separate permissions for the use of a CMK that provides added protection against unauthorized access to your objects in Amazon S3.
SSE-KMS also provides you with an audit trail showing when and who used the CMK. Additionally, you can choose to create and manage customer-managed CMKs or use AWS-managed CMKs that are unique to you, your service, and your Region.
SSE-C:
Server-Side Encryption with Customer-Provided Keys (SSE-C)
With Server-Side Encryption with Customer-Provided Keys (SSE-C), you manage the encryption keys and Amazon S3 manages the encryption, as it writes to disks, and decrypts when you access your objects. With this option, the customer is responsible for managing and rotating the keys, and without access to these keys, the Amazon S3 data can not be decrypted.
Server-side encryption is about protecting data at rest. Using server-side encryption with customer-provided encryption keys (SSE-C) allows you to set your own encryption keys. With the encryption key you provide as part of your request, Amazon S3 manages both the encryption, as it writes to disks, and decryption, when you access your objects. Therefore, you don't need to maintain any code to perform data encryption and decryption. The only thing you do is manage the encryption keys you provide.
When you upload an object, Amazon S3 uses the encryption key you provide to apply AES-256 encryption to your data and removes the encryption key from memory. It is important to note that Amazon S3 does not store the encryption key you provide. Instead, it is stored in a randomly salted HMAC value of the encryption key in order to validate future requests. The salted HMAC value cannot be used to derive the value of the encryption key or to decrypt the contents of the encrypted object. That means, if you lose the encryption key, you lose the object.
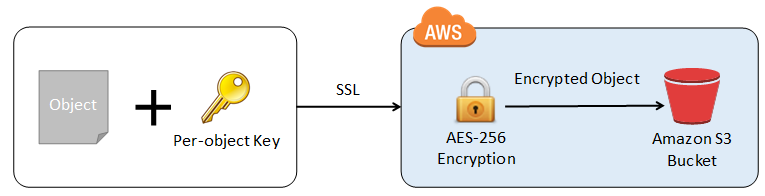
- Client-side encryption: you encrypt and decrypt AWS doesn't do anything.
Conclusion
In conclusion, AWS S3 is a versatile and powerful storage service offered by Amazon Web Services. With its scalability, durability, and cost-effectiveness, S3 has become a preferred choice for individuals and businesses looking to store and manage their data in the cloud. By providing features such as object storage, data security, versioning, and replication, S3 offers a comprehensive solution for various use cases, including data backup, web hosting, content distribution, and big data analytics. Embracing AWS S3 can empower organizations to harness the full potential of cloud storage and accelerate their digital transformation journey.